

Anthropic’s newest AI model arrives at a pivotal moment.
While tech headlines buzz with DeepSeek, OpenAI and Google releases, Claude 3.7 Sonnet takes a different approach. Rather than joining the arms race for ever-larger models, Anthropic has built something more pragmatic: a system that adapts to solve real-world business problems.
Breaking the Binary: Rethinking AI Reasoning
Tech giants have broadly split their offerings into two camps: quick-response models for everyday tasks and special “thinking” models for complex problems. Anthropic seeks to differentiate itself by rejecting this division.
Claude 3.7 Sonnet breaks the pattern with a dial rather than a switch, letting Pro subscribers fine-tune exactly how long Claude ponders a question. This ranges from rapid responses to deep analysis, which uses all 128,000 available tokens.
Anthropic CEO Dario Amodei has dismissed the black-and-white contrast between models that reason, versus ones that do not. He argues that reasoning can emerge gradually within an LLM, as opposed to being conjured up like an on/off switch. This philosophy appears to be behind the customisable reasoning feature in Claude 3.7 Sonnet.
Development Teams: Addressing Technical Bottlenecks
Software companies face pressure to deliver complex products with smaller teams. Claude 3.7 Sonnet could address this directly.
Unlike previous AI coding assistants that might excel only at generating snippets, Claude could potentially handle more of the development cycle – from initial planning to maintenance and refactoring. Its benchmark scores in agentic coding (70.3%) substantially outperform OpenAI o1 (48.9%), OpenAI o3-mini (49.3%), and DeepSeek R1 (49.2%).
The accompanying Claude Code preview supports this focus, functioning as a command-line interface that connects to version control systems. Early tests show that Claude Code completes tasks in a single pass that would otherwise take 45 minutes.
Great News for Data Journalists and Publishers
For media organisations battling content demands and shrinking newsrooms, Claude 3.7 Sonnet could offer more than just another writing tool, helping writers ideate and fuelling their innate creativity.
Data journalists could leverage Claude to identify patterns across large datasets, cross-reference claims against source material, and extract meaningful narratives from information streams. The ‘extended thinking’ capability will prove valuable for investigative reporting, where connecting disparate facts is essential.
Publishers might use such a system to analyse content performance patterns, helping editorial teams make more informed decisions about future coverage.
Law Firms: Document Analysis Applications
Legal practices operate in a world of overwhelming documentation. For them, Claude’s value could start with processing but extend to more substantial analytical assistance.
Commercial law firms might use Claude to analyse contract portfolios for risk exposure across different regulatory scenarios – work that typically requires a lot of human resource.
The shift from basic document processing to more nuanced analysis represents a potential transformation: law firms using Claude 3.7 Sonnet could identify precedent patterns across jurisdictions, assess litigation risks, and draft specialized legal arguments based on case law.
Safety First
While competitors showcase capabilities, Anthropic has invested in safety measures. This focus could become increasingly valuable as organisations integrate AI deeper into critical operations.
Anthropic has conducted extensive testing and evaluation of Claude 3.7 Sonnet, working with external experts to ensure it meets standards for safety, security and reliability. The safety card for this release discusses new safety results in several categories, including emerging risks from computer use and potential safety benefits from reasoning models.
Competition Landscape: The Reasoning Revolution
Claude 3.7 Sonnet enters a field that includes OpenAI’s o1 and o3-mini, DeepSeek R1, and Grok 3 Beta. The benchmark data reveals a competitive picture, but shows Claude’s latest offering on top of the pile in several criteria:
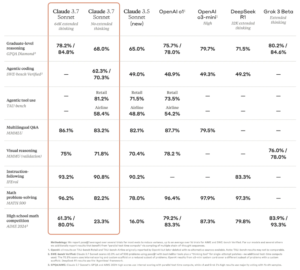
In graduate-level reasoning (GPQA Diamond), Claude (84.8% with extended thinking) matches Grok 3 Beta (84.6%) and outperforms OpenAI o1 (78.0%). Where Claude performs particularly well is instruction-following (IFEval), scoring 93.2% – well above DeepSeek R1’s 83.3%.
A large performance difference appears in high school math competitions (AIME 2024), where Claude’s score jumps from 23.3% without thinking mode to 80.0% with it enabled – demonstrating the impact of its reasoning capabilities.
While math problem-solving sees other models edge out Claude (OpenAI o3-mini leads at 97.9% versus Claude’s 96.2%), the overall picture shows a model delivering competitive performance with flexibility.
The Industry Proposition
Claude 3.7 Sonnet arrives at £3 per million input tokens and £15 per million output tokens, with various discounting options. Available through Anthropic’s API, Amazon Bedrock, Google Cloud’s Vertex AI, and directly via Claude.ai; it offers deployment paths for organisations of various sizes.
As industries from publishing to software development explore the possibilities, Claude 3.7 Sonnet’s promise lies not just in benchmark performance but in solving business problems – something Anthropic’s Economic Index suggests may matter more than technical specifications alone.
Join the AI Today Linkedin group to get involved and share your thoughts





